
はじめに
VLM(Vision Language Model)は「画像を見て言葉で説明するAI」です。このAIをAPIとして呼び出せば、自分のWebアプリに画像解析機能を組み込むことができます。
本記事では、画像をアップロードすると内容を日本語で説明してくれるWebアプリをNext.jsとOpenAI APIで構築する手順を解説します。
完成するアプリのイメージ:
- ユーザーが画像ファイルをアップロード
- 「解析する」ボタンを押す
- GPT-4oが画像の内容を日本語で説明して表示
必要なもの
- Node.js v20以上(推奨: v20 LTS)がインストールされたPC
- OpenAIのAPIキー(platform.openai.comで取得・クレジット購入が必要)
- ターミナル(Mac/Linux)またはコマンドプロンプト・PowerShell(Windows)の基本操作
Node.jsバージョンについて:Next.js 15以降はNode.js v20以上が必須です。v18・v19では Tailwind CSS のネイティブバイナリが欠落しビルドエラーになる場合があります。nvmを使っている場合はプロジェクトルートに
.nvmrcファイルを作成し20と記述しておくと、チームで同じバージョンを使えます。
ステップ1:プロジェクトの作成
ターミナルを開き、以下のコマンドを実行します。フラグを明示することで対話形式の質問をスキップできます。
npx create-next-app@latest vlm-app --typescript --tailwind --app --no-src-dir
cd vlm-app--typescript:TypeScript を使用--tailwind:Tailwind CSS を使用--app:App Router を使用--no-src-dir:src/ ディレクトリを作成しない(ファイルパスがapp/から始まるシンプルな構成)
次に、OpenAI公式のNode.js SDKをインストールします。
npm install openaiステップ2:APIキーの設定
プロジェクトルートに .env.local というファイルを作成し、APIキーを記載します。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx.gitignore にはデフォルトで .env* が含まれており、.env.local はGitにコミットされません。ただしチームや公開リポジトリでは、テンプレートファイルを別途用意しておくと便利です。
.gitignore に以下を追記してください(!.env*.example で example ファイルをGit管理対象に戻します):
.env*
!.env*.exampleそして .env.local.example を作成しておきます:
OPENAI_API_KEY=your_api_key_hereこのファイルをリポジトリにコミットしておくと、チームメンバーが必要な環境変数をひと目で把握できます。
ステップ3:API Routeの作成
Next.jsのAPI Routeを使い、画像をOpenAIに送信して説明文を受け取るサーバーサイド処理を作ります。
app/api/analyze/route.ts を新規作成し、以下の内容を記述します。
import { NextRequest, NextResponse } from "next/server";
import OpenAI from "openai";
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
export async function POST(req: NextRequest) {
const { imageBase64 } = await req.json();
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{
role: "user",
content: [
{
type: "image_url",
image_url: {
url: imageBase64,
},
},
{
type: "text",
text: "この画像に何が写っているか、日本語で詳しく説明してください。",
},
],
},
],
max_tokens: 500,
});
const description = response.choices[0].message.content;
return NextResponse.json({ description });
}ポイント解説
imageBase64は、クライアント(ブラウザ)から送られてくる画像データをBase64エンコードした文字列です。OpenAI APIは画像URLまたはBase64形式のどちらかで画像を受け取れます。今回はファイルアップロードに対応するためBase64を使います。
ステップ4:フロントエンドページの作成
app/page.tsx を以下の内容で置き換えます。
"use client";
import { useState } from "react";
export default function Home() {
const [imageBase64, setImageBase64] = useState<string | null>(null);
const [preview, setPreview] = useState<string | null>(null);
const [result, setResult] = useState<string | null>(null);
const [loading, setLoading] = useState(false);
const handleFileChange = (e: React.ChangeEvent<HTMLInputElement>) => {
const file = e.target.files?.[0];
if (!file) return;
const reader = new FileReader();
reader.onloadend = () => {
const base64 = reader.result as string;
setImageBase64(base64);
setPreview(base64);
setResult(null);
};
reader.readAsDataURL(file);
};
const handleAnalyze = async () => {
if (!imageBase64) return;
setLoading(true);
setResult(null);
try {
const res = await fetch("/api/analyze", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ imageBase64 }),
});
const data = await res.json();
setResult(data.description);
} catch (err) {
setResult("エラーが発生しました。もう一度お試しください。");
} finally {
setLoading(false);
}
};
return (
<main className="max-w-2xl mx-auto px-4 py-12">
<h1 className="text-2xl font-bold text-gray-900 mb-2">
画像解析アプリ
</h1>
<p className="text-gray-500 mb-8 text-sm">
画像をアップロードすると、AIが内容を日本語で説明します。
</p>
<div className="border-2 border-dashed border-gray-300 rounded-xl p-8 text-center mb-6">
<input
type="file"
accept="image/*"
onChange={handleFileChange}
className="hidden"
id="file-input"
/>
<label
htmlFor="file-input"
className="cursor-pointer inline-block bg-blue-600 text-white px-6 py-2 rounded-lg font-medium hover:bg-blue-700"
>
画像を選択
</label>
{preview && (
<img
src={preview}
alt="プレビュー"
className="mt-4 max-h-64 mx-auto rounded-lg object-contain"
/>
)}
</div>
<button
onClick={handleAnalyze}
disabled={!imageBase64 || loading}
className="w-full bg-violet-600 text-white font-bold py-3 rounded-xl hover:bg-violet-700 disabled:opacity-40 disabled:cursor-not-allowed"
>
{loading ? "解析中..." : "解析する"}
</button>
{result && (
<div className="mt-6 bg-gray-50 border border-gray-200 rounded-xl p-5">
<p className="text-sm font-semibold text-gray-700 mb-2">
AIの説明
</p>
<p className="text-gray-800 leading-relaxed text-sm whitespace-pre-line">
{result}
</p>
</div>
)}
</main>
);
}ステップ5:動作確認
ターミナルで開発サーバーを起動します。
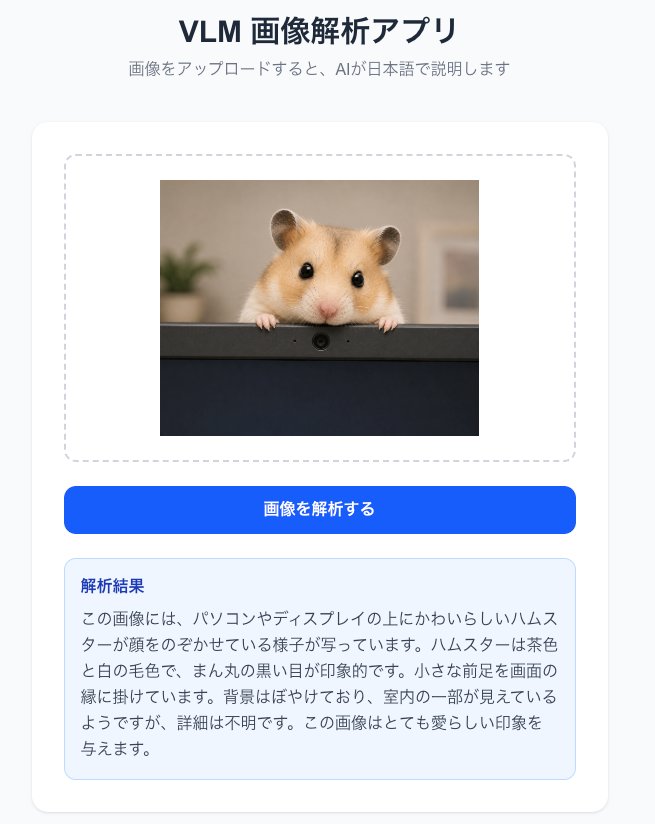
npm run devブラウザで http://localhost:3000 を開き、画像ファイルを選択して「解析する」ボタンを押してみましょう。数秒後にAIの説明文が表示されれば成功です。
トラブルシューティング
実際に構築する際によく遭遇するエラーとその解決策をまとめます。
エラー①:Cannot find native binding
Error: Cannot find native binding原因:Node.jsのバージョンを途中で切り替えた場合など、異なるバージョンでインストールされたネイティブバイナリが残っていると発生します。
解決策:node_modules と package-lock.json を削除してから再インストールします。
rm -rf node_modules package-lock.json
npm installWindowsの場合:
rd /s /q node_modules
del package-lock.json
npm installエラー②:429 quota exceeded
Error 429: You exceeded your current quota原因:OpenAI APIのクレジットが不足しています。APIキーを取得しただけではクレジットは付与されません。
解決策:OpenAIの billing 画面(platform.openai.com/account/billing)でクレジットを追加してください。開発・テスト用途であれば $5〜$10 程度から始められます。
コードの仕組みを理解する
データの流れ
- ユーザーが画像を選択
- FileReaderがJPEG/PNGをBase64文字列に変換
- ブラウザからNext.jsのAPI Route(/api/analyze)にPOSTリクエスト
- API RouteがOpenAI APIに画像+プロンプトを送信
- GPT-4oが画像を解析して説明文を返す
- ブラウザに結果を表示
なぜサーバーサイドでAPIを呼ぶのか
OpenAI APIキーをブラウザのJavaScriptに直接書くと、ソースコードを見れば誰でもキーを盗める状態になります。Next.jsのAPI Routeを経由することで、キーをサーバー側にのみ保持し、クライアントには秘密にできます。
応用アイデア
このアプリの構造を応用すれば、さまざまなサービスに発展させられます。
名刺読み取りツール
プロンプトを「この名刺に書かれている氏名・会社名・電話番号・メールアドレスをJSON形式で抽出してください」に変更するだけで、名刺情報の自動取得ツールになります。
レシート家計簿
「このレシートの日付・店名・合計金額・品目一覧をJSON形式で返してください」とすれば、レシートの自動仕分けアプリに応用できます。
製品外観検査サポート
「この製品画像に傷・汚れ・変形が見られるか判定してください」とすることで、簡易的な品質チェックツールになります。
多言語対応
プロンプトの最後を「英語で説明してください」に変えるだけで、多言語対応の説明生成ツールになります。
コスト管理の注意点
OpenAI APIは従量課金のため、画像1枚あたりの費用を把握しておくことが重要です。
GPT-4oの場合、標準解像度(512×512相当)の画像1枚あたり約85トークン(約$0.0002)です。月1,000枚処理しても$0.20程度と非常に安価ですが、高解像度画像や大量処理の場合はコストが跳ね上がるため、OpenAIのUsageダッシュボードで定期的に確認しましょう。
また、開発中は意図しないリクエストを防ぐために max_tokens を適切に設定し、月次の利用上限(Usage Limit)をOpenAIの設定画面で指定しておくことを強くおすすめします。
まとめ
VLMをWebアプリに組み込む最小構成は「フロントエンド(画像選択・表示)+API Route(キーを保護してOpenAI呼び出し)」の2層で実現できます。
今回のコードはわずか100行程度ですが、プロンプトを変更するだけでさまざまな業務ツールに応用できます。まずは手元のPCで動かしてみて、「AIが画像を言葉にする」体験を実感してみてください。その感覚が、次のビジネスアイデアにつながるはずです。
本記事のソースコードは GitHub(KentoFukui/vlm-webapp) で公開しています。クローンしてすぐに動かせる状態にしていますので、ぜひ参考にしてみてください。